概要
中納言による「現代日本語書き言葉均衡コーパス(BCCWJ)」または「日本語歴史コーパス」の検索結果をもとに、検索語の前後にどのような表現がよく現れるかを分析します。具体的には、検索語の直前・直後のN-gram(N個の短単位または長単位の連続)および検索語を前後からはさむN-gramの組の頻度順の一覧を作成し、エクセルで表示します。語句の用法やコロケーションの考察・分析を容易にします。最新バージョンはBNAnalyzer 1.80です。(2013/6/26)
[ お知らせ ]
◇ BCCWJの特性と使用上の注意について述べた拙文2件についてはこちらをご覧ください。
- 本ソフトウェアは無保証です。自己責任でご使用ください。
- 本ソフトウェアはエクセルのインストールされたWindows上で動作します。作成とメインの動作確認は日本語版Windows XP+Excel 2003で行い、Windows Vista/7/8、Excel 2007/2010/2013の環境でも動作を確認しています。英語、簡体中文、繁体中文(台湾)の各版のWindows XPでの動作も確認しています。
- 英語版Windowsの場合はこちらの手順に従って設定を行う必要があります。また、Japanese Language Packの追加を要する可能性があります。
- 本ソフトウェアの作成にはRuby 1.8.7(http://www.ruby-lang.org/)とExerb 5.3.0(http://exerb.sourceforge.jp/)を使用させていただいています。
- 本ソフトウェアは法的に保護された著作物です。改変・転載・再配布等はご遠慮ください。
インストール
次のリンクをクリックし、表示される「ファイルのダウンロード」ダイアログで[実行]ボタンを押します。環境によって[実行]ボタンが出ない場合は、まずファイルをディスク上に保存し、それをダブルクリックして実行します。(実行時、セキュリティの警告には「実行する」や「はい」などで応じてください。)続いて表示される「BNAnalyzerのインストール」のダイアログで[OK]ボタンを押すと、デスクトップにアイコンが2つ作られます。それぞれを単純版、circumcollocate版と呼びます。(インストール後に「このプログラムは正しくインストールされなかった可能性があります」というメッセージが出ることがありますが、問題なくインストールされています。「このプログラムは正しくインストールされました」で応じてください。)BNAnalyzerのインストール(公開停止)
※公開再開時期は未定です。この件に関わる連絡・質問はお控えください。

- リンクをクリックした後の手順はブラウザの種類やバージョンによって異なる可能性があります。必要に応じて適宜対処してください。
- 最近のブラウザやセキュリティソフトはソフトウェアをスムーズにインストールさせてくれないことがあります。Internet Explorerの場合、操作を進めるうちに現れる「詳細オプション」や「詳細情報」のリンクをクリックした先に「実行」ボタンがあります。
- 更新の場合は、リンクをクリックした後、上書きの確認に対して「はい」で応じてください。なお、本ソフトウェアを実行中の場合はいったん終了したうえで更新します。
- アンインストールはアイコンをごみ箱に移すだけです。
用法
中納言の検索結果から検索語の前後のN-gramの一覧を得るには次のようにします。1) 中納言(日本語歴史コーパスはこちら)で[検索結果のダウンロード]によって検索結果をディスク上に保存
2) そのファイルをBNAnalyzerのアイコンの上にドラッグ&ドロップ
- 検索結果保存時に自動的に付くファイル名はkwic-??????.txtですが、検索内容の分かるファイル名にするのがよいでしょう。日本語版や簡体中文版のWindowsの場合、ファイル名には仮名・漢字も使用可能です。台湾繁体版Windowsでは漢字は使えますが仮名は使えません。
- 中納言の「ダウンロードオプション」は次のように指定します。
システム:Windows、文字コード:UTF-8、改行コード:CRLF、「~ZIP圧縮を行わない」:チェック - 日本語版および台湾繁体版のWindowsのでは、ダウンロードしたファイルをメモ帳かテキストエディタで開き、Ctrl+Aで全選択してCtrl+CでコピーしてからBNAnalyzerのアイコンをダブルクリックすることで処理するという方法も可能です。ただし、この方法ではShift_JISに含まれない文字は文字化けないし消失します。
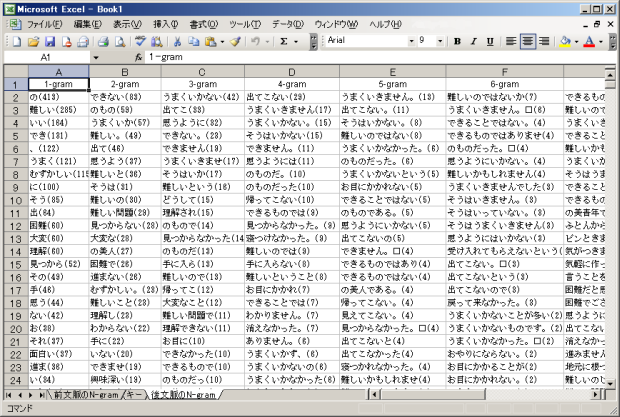
この一覧は、「なかなか」の後には「の」「難しい」「いい」(1-gram)、「でき-ない」「の-もの」「うまく-いか」(2-gram)、「うまく-いか-ない」「出-て-こ」「思う-よう-に」(3-gram)などの表現がよく現れることを示しています。
circumcollocate版も用法は同じです。次の図は、語彙素「惜しむ」の検索結果を分析して得られる結果の一部です。
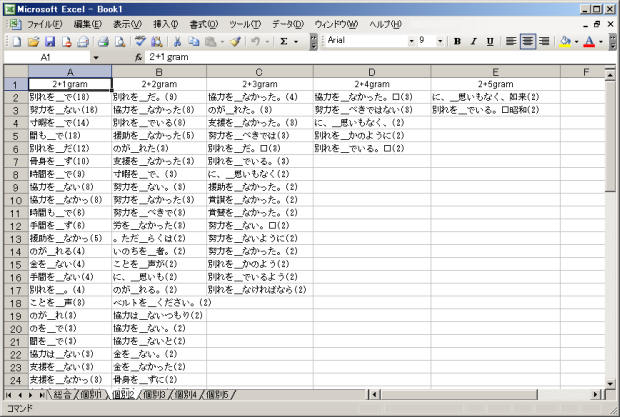
この一覧の例えば左端の列からは、「惜しむ」が「別れを惜しん{で/だ}」「{寸暇/時間}を惜しんで」「{努力/協力}を惜しまない」「{骨身/手間}を惜しまず」などの形でよく使われることを知ることができます。circumcollocateは、「寸暇を惜しんで」「努力を惜しまない」「骨身を惜しまず」のように「惜しむ」を前後からはさむように現れる2表現の慣習的な組合せを、「惜しむ」の1つの共起表現として捉えたものです(circum-は取り囲む、collocateは共起表現の意)。
- circumcollocateに関する詳細についてはこちらにある拙論をご覧ください。分析結果の「個別」のシートで“2+1gram”などのように表示しているのは、“2-gram+1-gram”の略記です。「総合」のシートの“4-gram”は“1+3gram”、 “2+2gram”、 “3+1gram”を合わせたものです。
- 検索は短単位検索・長単位検索・文字列検索のいずれによってもかまいません。検索時、文脈中の区切り記号は「|」の指定のままにしておきます。
- 頻度1のN-gramは表示しません。
- 空白は「□」で表示します。
- データ量が多いと分析に時間がかかります。処理が終わるまでエクセルを操作しないでお待ちください。
- 用例が数万件に上るときはドラッグ&ドロップ方式によってください。処理可能なデータ量の上限は環境とデータに依存します。
- 処理終了時に表示されるポップアップメッセージは数秒後に自動的に消えます。
- 分析結果のディスクへの保存は行いません。必要に応じて手動で保存してください。
補足説明
BCCWJの短単位・長単位については国立国語研究所コーパス開発センターのWebサイトに簡単な解説と詳細な規程集が掲載されています。N-gramの集計に疑問がある場合は検索結果の内容を確認してください。そこに何らかの理由があるはずです。特に、中納言で検索対象を指定しないでBCCWJ全体を検索すると、Yahoo!ブログなどのサブコーパスにおけるデータの重複により一般性の低いN-gramが多数回現れ、奇妙な分析結果になることがよくあります。


これらの例に見る「見つけたいならYahoo!縁結び」や「あなたの気持ちに殉じて自分は」などの高頻度N-gramは、ブログ記事の書き手によってその都度書かれたものではなく、機械生成ないし複製によるものです。
BCCWJ使用時に、均衡性の考慮から明確な基準に基づいて収集された出版物のデータに、Yahoo!ブログなどのデータを単純に加えて使うのは、そもそも“均衡”コーパスのまっとうな用法ではありません。機械生成などの“用例”をそれと知らず通常の用例と同列に扱ってしまうことのないよう、中納言では検索対象(少納言ではメディア/ジャンル)を目的に応じて適切に指定したうえで検索する必要があります。話しことばの書き起こしであり、やはり異質性の高い国会会議録のデータも、“書き言葉”コーパスの他の部分との不用意な併用は避けるべきでしょう。
詳しくは「お知らせ」のところにリンクしている拙文をご覧ください。
拙作関連ソフトウェア
| 日本語KWIC索引生成ソフトウェア KWIC | 任意の日本語テキストから語句を検索し、KWIC索引を生成 |
| KWIC索引のソート sortKWIC | KWIC索引をソート |
| KWIC索引の原文参照 Source Text Retriever | KWIC索引の用例の原文テキストを参照 |
| KWIC索引の引用 quoteKWIC | KWIC索引の用例を論文などへの引用に適した体裁でWordに格納 |
| BCCWJ N-gram分析 BNAnalyzer | 中納言の検索結果に基づいて表現の共起傾向を分析 |
| BCCWJテキスト抽出 bccwj2text | BCCWJ-DVD版からコーパス全サンプルのテキストを抽出 |
| 日本語用例検索サイト | 青空文庫所収の文学作品約3,400件から日本語の用例を検索 |
| 日本語研究文献検索サイト | 日本語研究文献を検索し、結果を見やすい書式で出力 |
| 文献ソートサイト | 文献リストを著者名または刊行年に基づいて並べ替える |
| 例文番号の付け直し Renumber | 言語学の論文の例文番号を付け直す(Word用) |
改訂履歴
1.00 作成(2012/7/5)1.10 circumcollocate版を追加(2012/7/22)
1.20 Unicode対応、非日本語版Windows対応、ドラッグ&ドロップ対応(2012/7/25)
1.30 検索結果のzipファイルの解凍を不要にした(2012/7/28)
1.40 中納言の改訂(1.0.5)に対応(2012/11/6)
1.50 日本語歴史コーパスに対応(2013/2/23)
1.60 中納言の改訂(1.1.0)に対応、zipファイル解凍機能を廃止(2013/5/31)
zipファイルを扱うdllのコピーが不要になりました。
1.70 台湾繁体版Windowsにおける問題を解決(2013/6/8)
1.80 Excel 2013の環境における問題を解決(2013/6/26)
- 環境やデータによって処理が正しく行われない場合、可能であればソフトウェアを修正します。検索結果をメールに添付してお送りください。その際、処理の手順、Windows・エクセルの種類やバージョンなどもお知らせください。
- 作者の環境では日本語歴史コーパスの中納言5.1.0では検索結果のダウンロードができず、検索結果がテキストエディタで開かれます。そのような場合はいったん検索結果をUTF-8で保存して処理するか、全選択&コピーの方法で処理するという方法によってください。
ソフトウェアのメニューに戻る